PDF通过标签方式分类研究
前言
在对文献进行爬虫时,使用的方法为利用相应的关键词进行下载,而此关键词仅为文章关键词中的全部关键词中的一个,其在文章中所占的比例并不一定为最高,即此关键词可能只是某个主问题的分枝,并不是文章的主要内容。除此之外,某些关键词再下载时可能会存在重复下载的情况或爬虫程序检测到相应的文献已经完成下载,对以此关键词为检索时并未下载。因此,对所有已经完成下载的文献按照其文章真正内容进行主要内容关键词的提取和排序显得极为重要,也为了后续本地数据库的建立打下基础,现对文献分类问题进行解决。为解决此问题,本项目采用了对pdf进行打标签、按照标签重要程度进行划分。以下为GitHub中主要的几个分类方法对应的项目,在此对各项目进行总结分析。
基于神经网络的PDF分类-Neural-pdf-classification
主要思路
也是需要进行深度学习训练的一种方法。大体思路为:从PDF中提取不同部分的数据,建立在前馈神经功能网络的基础上(Feedforward Neural Network)(有对应的循环神经网络(RNN可以好好看看wiki)-还有很多模型),并使用误差反向传播(Backpropagation)进行训练 。(单层神经网络必须仅仅使用图像中的像素的强度来学习一个输出一个标签函数。多层的网络克服了这一限制,因为它可以创建内部表示,并在每一层学习不同的特征。-此处可以除了文字层,增设表格层和图像层,也可通过图题和表题进行划分。)
项目介绍
神经网络对信息识别需要将PDF抽象化,即机器不会明白其中的词语的含义,但是这些单词都有机器能识别的特征。
作者对一个PDF文件中机器可以识别的信息进行了分类。以后就叫“特征(Features)”


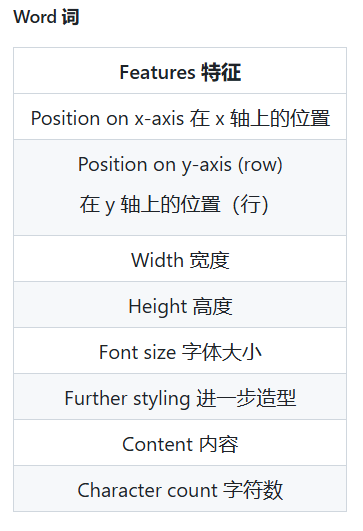
解释数据-识别数据
我们把对PDF的分类就简化为了对以上的特征进行分类。想要分类,就需要先识别,哪个是哪个呢,这就是第一个需要解决的问题。我们不能只对某一个具体的文章进行判断,不能只因为这个文章标题有7个字符、字体大小为150px就把对标题的识别条件设置为这样,我们还需要考虑到其他文章。因此我们需要找到所有文章标题的共同点/和其他部分(正文)不同的部分。如:“标题很可能是文档中最大的文本。它不太可能经常使用,而且可能相对较短。”
神经网络简介
神经网络(在本例中为前馈网络)接收一定数量的数字输入,通过一定数量的隐藏层对其进行处理,并输出一定数量的数字结果。每个圆圈代表一个神经元。神经元之间的箭头(或突触)表示它们的值如何在网络中传播。每次该值通过突触时,它都会乘以一个权重。这个权重决定了该值对最终输出的重要性。隐藏层的神经元是奇迹发生的地方。这些中间神经元的数量可以变化,隐藏层神经元的数量与输入或输出的数量无关。还可以有多层隐藏层,让网络在最终给出输出之前进行更多的计算。
权重可以通过硬编码或训练来确定。教神经网络执行正确的计算本身就是一个学科需要单独学习(终究还是得学)。在本文中,我们将简要概述反向传播。反向传播为网络提供输入,并计算网络输出与预期结果之间的差异。这个差异值用于调整网络的权重,使其能够逐步计算出更准确的输出
使用神经网络对文章进行分类-使用现有的分类好的作为训练数据集
选择输入
例如对标题,我把标题的以上方面的信息进行假设,如:
1、位置-首页上方,不会在后几页的底部。
2、字体大小-比其他所有的字体都大。
3、长短-一般较正文来说短。
在确定时,还是需要主要考虑这些假设的普适性,即适合所有的pdf文章。
确定预期的输出
我们需要提前给他一个答案,一个我们所期待的输出的形式。使用这些数据集进行训练。如图为训练数据集的表格。
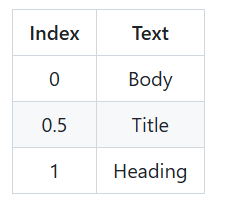
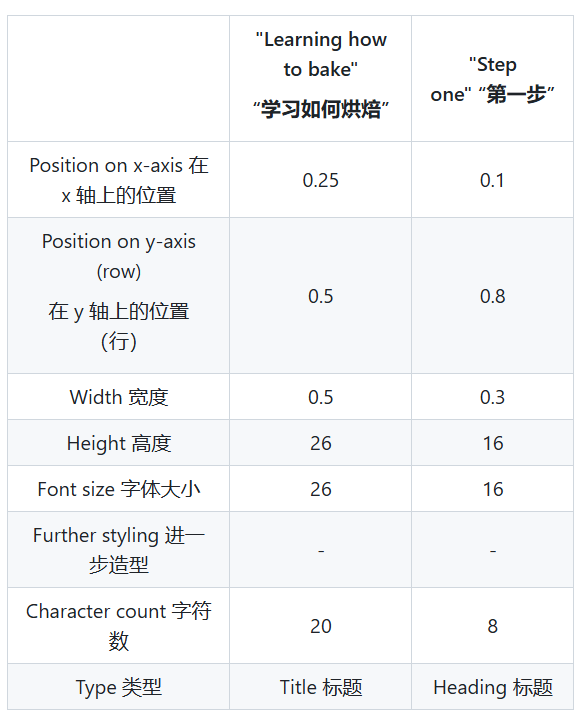 此表为一种数据集的形式,我们可以看到我们的输入为数字形式,与此同时,我们的输出也会是数字形式,我们需要对输出的数字形式进行索引,对应到其名称,如输出参数为0,则为正文内容。
此表为一种数据集的形式,我们可以看到我们的输入为数字形式,与此同时,我们的输出也会是数字形式,我们需要对输出的数字形式进行索引,对应到其名称,如输出参数为0,则为正文内容。
训练
我们有了输入和输出,接下来就是训练,训练也有训练时需要确定的参数,这些参数会影响到最后我们训练结果的准确率。如下图的准确率是很高的。
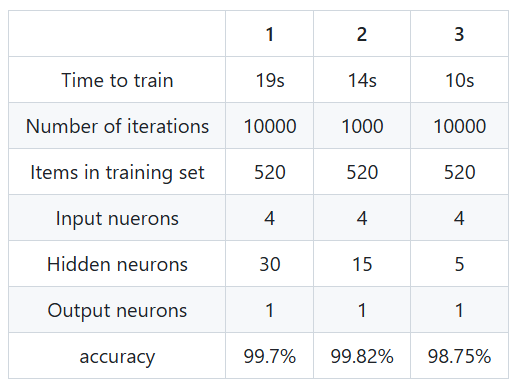
展望
使用此神经网络的方法进行训练,我们还可以进行优化,如为了改进信息提取,可以采取许多步骤。可以教授和预测文本中的主题,可以提取关键字等等。
基于文本出现频率的文档分类/识别
朴素贝叶斯、随机森林、XGBoost、Word2Vec、Doc2Vec
前言
此种方法作者用于区分文档类型,如文章、财务报告、人力资源、合同等不同类别。对文章内容细化区分的能力可能较弱。
项目介绍
原始数据转换和提取
首先对文档进行标准化,转化为统一格式,可以是pdf、word、html等,但是其转化的难易程度及对文档内容提取的难易程度也不同。
然后对文本进行预处理,如整理为全部小写、删除字符、删除某些特定的词,将某些时态的词换成同一时态的词。
特征工程
计数出现最多次数几个单词。
数据分析
对分类的结果进行统计。我们也会遇到这种数据集不平衡的情况,作者解决的方式为过采样或欠映射。
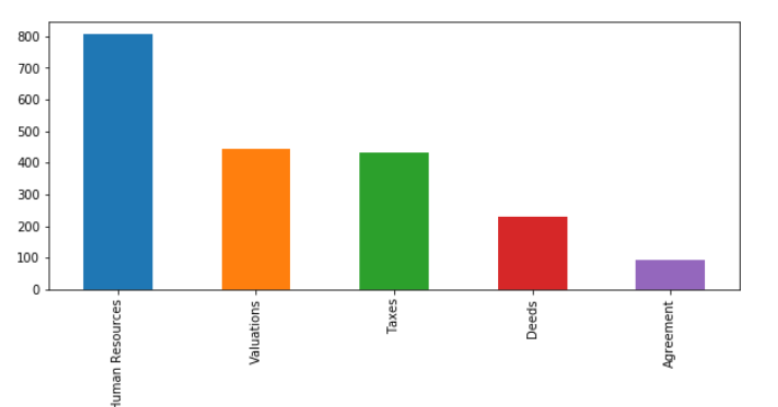
构建模型和测试精度
为这个分类问题构建了 5 个不同的模型(朴素贝叶斯、随机森林、XGBoost、Word2Vec、Doc2Vec),并将它们的表现与类预测进行了比较。您可以在 jupyter 笔记本中查看详细信息及其性能。
模型测试
最后总得验证一下子,他以达到90%为目的
无监督文本分类
github原文,为对某文章的实现,基础算法并加以优化。
使用场景
对大批量无标注文本进行快速的预分类,以研究样本分布情况和分类标注规则,提高后续的精细化标注和使用复杂模型进行迭代的效率。
项目介绍
四部分
1. 关键词预标注
使用初始关键词(seed keywords)对文本集进行预标注。
2. 多项式朴素贝叶斯
在预标注的文本集上,对类别先验概率P(category)和单词的后验概率P(word|catrgory)进行估计,进而计算出P(category|document)
3. 分层收缩hierachical shrinkage
利用分类的层级关系,在估计P(word|category)时将父分类样本包含进去,缓解特征稀疏的问题
4. EM迭代
步骤2和步骤3涉及的参数均利用EM迭代进行更新并得到收敛
项目操作手册
构建初始关键词体系
关键词格式
对我们构建的关键词设定相应的分级设定,并给出相应的样板格式。
构建经验
首先定义分类,然后可根据直觉、经验以及对样本的观察获取各分类的初始关键词。
按原论文所述,关键词的精确和召回之间,优先保证精确。即多一些特征显著的词,不要使用停用词。
原论文所做实验中,初始关键词覆盖率为41%,本项目实验中初始关键词覆盖率为44%。
如分类结果不佳,首先检查样本集中是否存在较多的未定义分类,或者存在容易混淆的分类,前者需要新增相应分类,后者可以考虑对易混分类进行统一或建立层级关系。最后考虑对关键词进行优化和补充。
训练模型
给定相应的参数和基础数据类型
最后对项目进行评价
对初始关键词、词典大小、shrinkage步骤、不同迭代轮数对项目训练结果的影响。